Ensemble Learning
What is Ensemble Learning
The Hundred-Page Machine Learning Book
Ensemble learning is a learning paradigm that, instead of trying to learn one super-accurate model, focuses on training a large number of low-accuracy models and then combining the predictions given by those weak models to obtain a high-accuracy meta-model.
- It is a machine learning technique that combines multiple models to improve the overall performance of the system.
- It can be computationally expensive and may require more resources than a single model.
Types
Bagging (Bootstrap Aggregating)
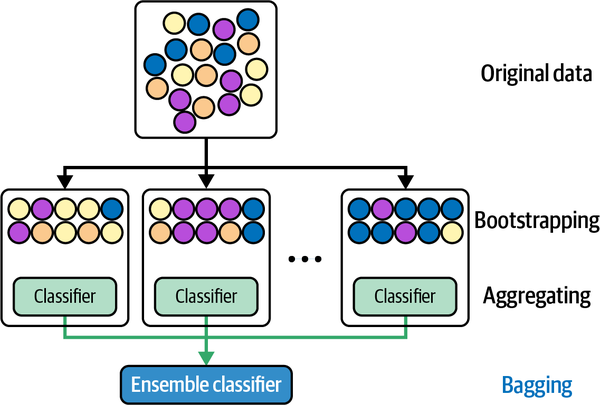
How it works
- Bagging is an ensemble learning method in which multiple models are trained independently on random subsets of the training data.
- The predictions of these models are combined using a simple majority vote (for classification) or an average (for regression) to make the final prediction.
- Bagging can improve the accuracy and stability of the model, especially when the individual models are prone to Underfitting vs. Overfitting#Overfitting.
- Additionally, it provides an internal validation method Out-of-Bag (OOB) evaluation:
- How OOB works:
- around 63% of the data points are included in the bootstrap sample for training one model, and the remaining ~37% of the data points are called OOB for testing the prediction accuracy
- since bagging includes multiple models, each data point will be OOB for some subset of models.
- The OOB score is the aggregated performance (e.g., accuracy for classification, R² for regression) across all these OOB predictions
- Why need OOB
- it's essentially "free" and quick to use, mostly for Decision Tree & Random Forest#Random Forest
- it's faster than Cross-Validation for medium-to-large datasets
- How OOB works:
Examples
- Decision Tree & Random Forest#Random Forest can be seen as a bagging method for decision trees
Boosting
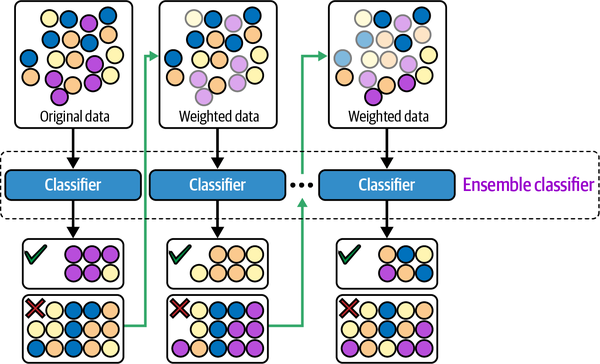
How it works
- Boosting is an ensemble learning method in which models are trained sequentially, with each new model attempting to correct the errors of the previous models.
- The final prediction is made by combining the predictions of all the models, weighted by their individual performance.
- Boosting can be effective in reducing the bias of the model (i.e. solving Underfitting vs. Overfitting#Underfitting), especially when the individual models are simple and have high bias.
Examples
- AdaBoost (Adaptive boosting)
- Gradient Boosting
Stacking
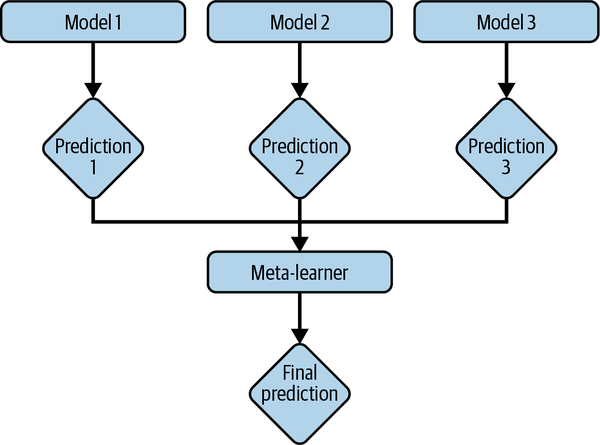
How it works
- train base learners from the training data then create a meta-learner that combines the outputs of the base learners to output final predictions
- take a majority vote (for classification) or an average (for regression) from all base learners to make the final prediction.
How to combine model predictions
- Averaging
- = averaging the prediction of base models - works for regression
- Majority vote
- = get the majority votes from base models - works for classification
- Stacking
- = use the prediction of a meta-model that takes the output of base models as input